


Artificial Intelligence Services

Custom Tagging Tools
In order to develop a good AI model we need high quality training data. We build custom tools using domain specific knowledge that can help you annotate content to get high-quality training data with ease. In general, the quality of the AI Model grows significantly with the quality and the size of the data set.
Our tools make tagging very simple! We design our tools to fit right inside your pipeline, which makes data management extremely simple.
Our Tagging tools can augment the annotation with AI and traditional programming, to ensure we have all the necessary data in all categories.
Our tools Govern
- Labeling – Setup, Effort, Accuracy & Speed
- Quality, Scope & Quantity
- What type of Data
- How much data is needed
- Data Augmentation
- Customized Annotation Tools are created based on the training.
- Annotation Tools are created to be part of the end to end pipeline
Our Process
- We integrate AI into custom tools which are tailored to your needs.
- We support various vision models
- We build specialized tagging tools for
- Object Detection
- Segmentation
- Classification
- Our custom tools fit right into the pipeline without needing much additional work on the client side.
- We can build a tool to leverage small amounts of annotated data and use this data to train the model. Deep Learning models require large amounts of data to accurately predict the output. We utilize the model trained on the smaller volume of data to augment the annotation by humans, which increases the efficiency and speed of labeling of the data.
Tagging/Labeling/Annotating can be very time consuming! Our tools can take the guesswork out of it, and track what is required. It will always have the data ready for Model Training.

AI Architecture
In order to have a good AI Model, you need to start with good AI Architecture. We can help you navigate it safely, and making the right decisions here goes a long way. One size doesn’t fit all.
The most fundamental question in model building is determining what you would like to predict.
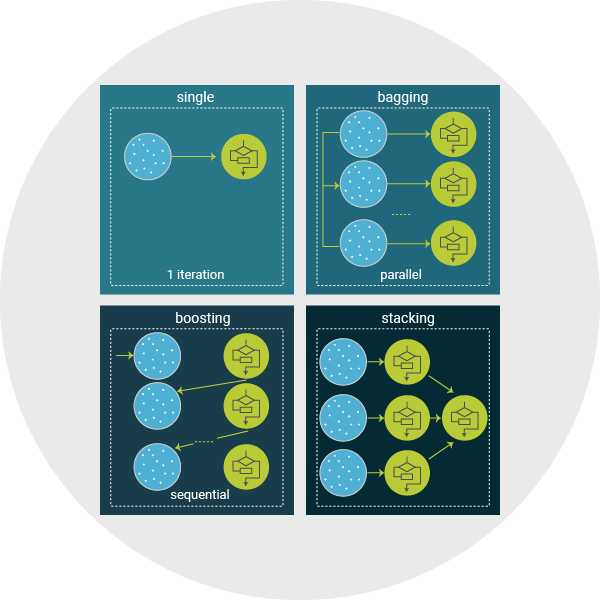
We favor Ensemble learning, with each model finding different patterns within the data to provide a more accurate solution. These techniques can improve performance, as they capture more trends, as well as reduce overfitting, as the final prediction is a consensus from many models. We use different techniques, depending upon the need: Bagging, Boosting & Stacking.
We can help you with all aspects of the AI System.
- Identifying the right training data
- Size of the data set
- Distribution of data in labels
- Distribution of data in Train/Dev/Test
- Choosing the right framework to train neural networks
- Optimize models for deploying them in edge devices or GPU servers for inference.
- Identifying the evaluation metrics of the model.
- Augmenting the model output using traditional programming
Model Training
Once we have collected the necessary data for training, we can commence the Model Training. Depending upon the training data set and what we are trying to predict, we can choose either to training from scratch, or we can perform Transfer Learning. Transfer Learning will expedite the training process significantly. The training begins only after we identify the right model architecture.
In order to get a good AI Model, there may be significant training required. This can be very time consuming and mistakes can be very costly. We use specialized techniques depending upon the size of data, and constantly test the model along the way, making necessary adjustments as needed.
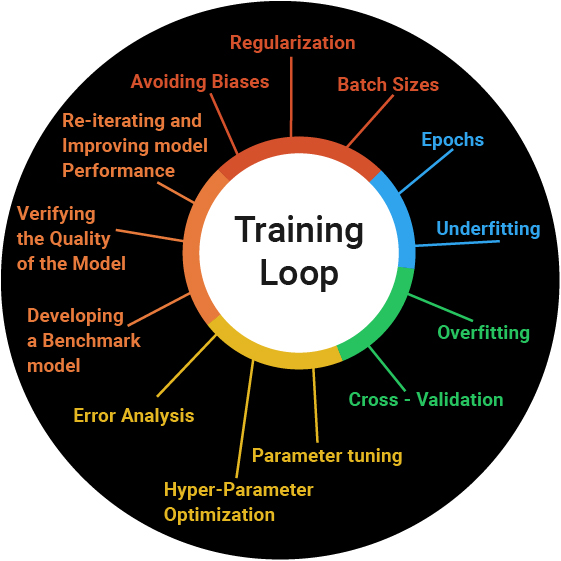
We look at a lot of aspects while training, and constantly monitor during the training process to ensure we get the desired results. Below are a few aspects that we monitor:
- Split the data correctly
- Avoiding Biases
- Regularization
- Batch Sizes
- Epochs
- Underfitting
- Overfitting
- Cross – Validation
- Parameter tuning
- Hyper-Parameter Optimization
- Error Analysis
- Developing a Benchmark model
- Verifying the Quality of the Model
- Re-iterating and Improving model Performance
Model Deployment
Once the best model is selected from the model training process, it needs to be integrated into the production environment to make inferences. Model Deployment is the most challenging process. Both the server and model need to be optimized to make the inference faster and reliable. Maintaining robust data pipelines are crucial to model deployment. Models needs to be compatible with the production environment, or it could lead to delaying the timeline of projects by days or weeks. Our experienced teams who deploy and maintain a number of deep learning models can seamlessly move models into production swiftly and efficiently.
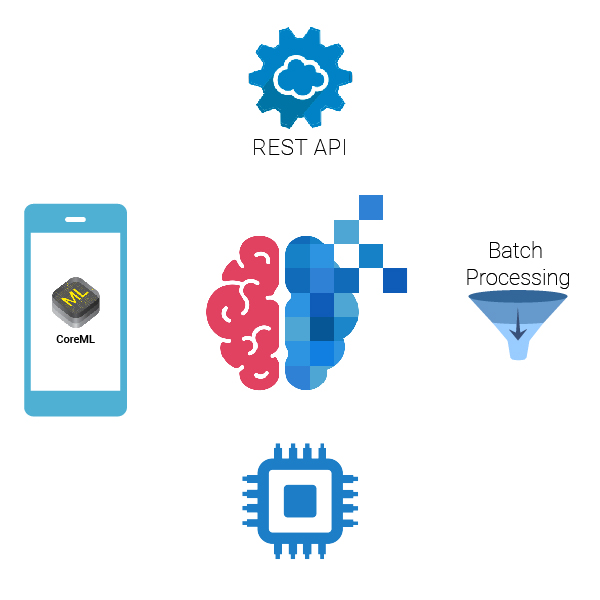
Deployment depends on the application and is different for various projects. Some of the models needs to be deployed on mobile for real-time evaluation, while others need to be deployed on servers. Regardless of the use case, our team can handle it. Our team has served models in following cases:
- REST API
- In Mobiles Device Applications
- Batch scoring
Deployed model needs to be constantly monitored for degrade in performance over time due to changes in the data or for server issues. In order to tackle it we have custom processes in place to continuously monitor the processed data and alerts any discrepancies.
Consulting
- Offsite/Onsite
- Our resources can be used as subject matter experts to communicate with your clients via email, phone call, in-person meetings, etc… or they can simply be used behind the scenes to complete tasks.
- Full Time: This individual will be available 40 hours per week to work on tasks as assigned.
- Hourly – as needed: This would be on an as needed basis to provide feedback, instruction, and input on various projects. We will do our best to provide services on short notice, but cannot guarantee same day availability.